
Recently there has been a surge in interest in digital humanities (DH) , making use of “big data” methods to collect information about humanistic subjects. A part of that surge is the Open Syllabus Project (OSP), which constructs rankings of texts according to how many times they are assigned in syllabi. According to the OSP creators’ description:
The OSP is an effort to make the intellectual judgment embedded in syllabi relevant to broader explorations of teaching, publishing, and intellectual history. The project has collected over 1 million syllabi, has extracted citations and other metadata from them, and is now pleased to make the Syllabus Explorer publicly available as a means of exploring this corpus. Looking ahead, the OSP’s goal is to expand the collection and make it more useful to authors, teachers, administrators, and students.
The OSP is assembled: “Primarily through the crawling and scraping of publicly-accessible university websites” and it has “…around 1.1 million syllabi, drawing predominantly from the past decade of teaching in the US.” While this number sounds impressive, the creators estimate that “…the total number of US, UK, Canadian, and Australian syllabi for the past 15 years is in the range of 80-100 million.” Therefore the OSP only covers about 1% of the English language syllabi from the UK and the former “white settler colonies” (Minus New Zealand and South Africa) of the British Empire. Therefore it hardly offers a complete sample of even the syllabi offered by American higher education institutions (Considering the large number of institutions in the USA). While we can’t know much about the limitations of the data set aside from this, it is still interesting to examine the results drawn from these 1.1 million syllabi.
As soon as I encountered the OSP I was intrigued by the relatively high ranking assigned to Capital (It is ranked 44th out of 933,635 texts) given how the text is afforded little respect among mainstream economists (especially in the USA!) and how few courses focusing on the text are taught lately. The OSP lets us examine what texts are assigned along with any given text, so we can see what texts are assigned in courses that also teach Capital. I performed some simple quantitative analysis of this data set and decided to publish my results here.
In the first place, I was struck how the OSP (aside from its lack of a complete sample) suffers from a common problem found in data sets “scraped” from online sources. That is, the problem of duplicate entries due to slight variations in titles across editions. For example we can see immediately that Capital is in fact under-represented in the total data set because of how differently titled editions disperse its number of assignments. We see “Capital: A Critique of Political Economy,” and “Capital, A Critique of Political Economy Vol. 2” listed as texts assigned with Capital! Apparently Capital is assigned alongside itself! While the total assignments represented by these faulty categorizations is quite small (104 vs. 1447 for the main “Capital” entry) this problem is endemic to the data set, so I had to do quite a bit of tidying up before I could examine the data. In the first place I removed the duplicate Capital entries, since we don’t know which volumes the main “Capital” entry refers to, we can’t say whether the distinction between Vol. 1 and Vol. 2 is meaningful or not. Then I aggregated the assignment counts of other duplicate entries (I could tell they were duplicates because of their similar titles and authors, in some cases I went and checked online to make sure). While I could only examine the top 100 entries listed here, I aggregated wherever I could. Big data promises a lot of academic labour saving, but if you want to get any meaningful results a lot of “cleaning” of the data set by expert workers is still required! Only time will tell if we will one day trust software to do this kind of aggregation work for us. Because it represents a mutation of the data set and therefore a destruction of information, it is usually looked upon with fear by researchers.
First let’s look at the top 10 texts that were assigned with Capital, ranked by their number of assignments:
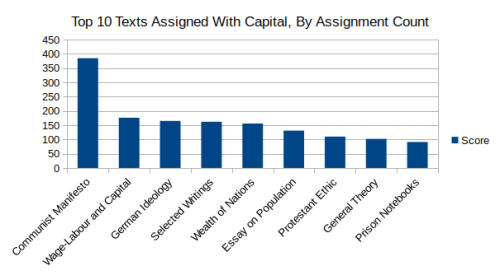
We can see that the top four texts are all written by Marx himself (That the Manifesto is ranked first is not surprising considering that it is the second more frequently assigned text in the entire data set!), followed by Smith’s Wealth of Nations and Malthus’ Essay on Population, both of which Marx refers to in Capital. This is followed by Weber’s The Protestant Ethic and the Spirit of Capitalism, which was heavily influenced by Marx, Keynes’ General Theory, which was written as a rebuttal to Marxist economic arguments of Keynes’ time, and finally Gramsci’s Prison Notebooks, one of the most famous 20th Century Marxist texts. Therefore (aside from Marx’s own work) we have two texts that influenced Capital, two that were influenced by it, and one that is opposed to it (Although Keynes’ work may have been indirectly influenced by Capital: Volume 2‘s reproduction schema).
Out of the works by Marx, we have the Manifesto, whose popularity is not surprising given its purpose as a political pamphlet for widespread distribution and political agitation, followed by Wage-Labour and Capital, which is a bit of a surprising choice but may be cited in order to explain Marx’s labour theory of value, The German Ideology, which is often assigned to explain the concept of historical materialism and the Marxist conception of ideology, and the Selected Writings, about which not much can be said.
Next let’s look at the top fifty texts that were assigned with Capital, ranked by number of assignments:
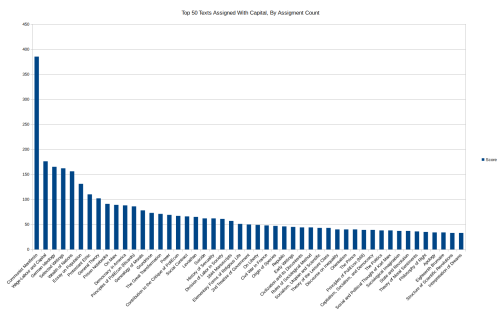
The overwhelming popularity of the Manifesto is much more obvious here, but we can also see that Marx’s most popular works noticeably surpass those of the other authors. The Wealth of Nations also slightly outstrips the rest of the pack, perhaps because it is often presented as the counter-point to Capital, perhaps because Marx cited it heavily (Although this seems unlikely considering the influence of Ricardo upon Marx not being clearly reflected in the ranking).
Next is the ranking of authors by the number of times their works were assigned in the top 50 set:

Marx is far and away the most assigned author here, which suggests that Capital is rarely taught in isolation as a definitive statement on Marx’s work. This no doubt has to do with the length and difficulty of the text, but it may also support my perception that courses on Capital are few and far between, and that instructors prefer to “cherry pick” certain chapters from Volume 1 in order to suit the purposes of their courses (For example Chapter 1 on commodity fetishism, Chapter 10 on the working day, Chapter 15 on machinery and modern industry, and the final chapters on primitive accumulation). In particular, Wage-Labour and Capital is an odd choice to teach alongside Capital because it represents an immature version of Marx’s labour theory of value. While I can only speculate on the matter, my hunch that this is because instructors want a simple text to refer to on the labour theory of value in order to “get it over with,” and no one chapter of Capital is very well suited to this purpose.
While no one work by Durkheim made it into the top 10, we can see that his aggregate score clearly put him in second place. This is likely because he is considered to be one of the great founding fathers of sociology along with Marx, so his work may often be taught along with Capital in introductory sociology classes. Engels gets a lower ranking than he should here because the data set does not list him as the co-author of the Manifesto and The German Ideology. As per-usual, Engels fades into Marx’s shadow! Foucault’s high ranking is again not surprising because he is conventionally taught as the thinker who surpassed Marx as a social theorist (For many years to declare oneself a Foucauldian was a way to declare radical credentials while distancing oneself from Marxism – In recent years some Marxists have been trying to settle the score). One interesting entry for his relatively low rank is Hegel, whose Philosophy of Right (No doubt taught alongside Marx’s critique) just barely got him into the group. While the debate over Hegel’s influence on Capital springs eternal, it apparently is not of much interest to instructors.
With these bar graphs out of the way, let’s take a look at some analysis of the disciplinary breakdown of the texts:

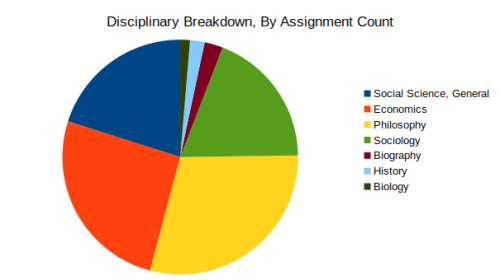
The first pie chart represents the number of texts from each discipline, while the second represents the proportion of assignments of each discipline. Admittedly, the second chart is more meaningful, while the first is more of a curiosity. Because I encoded the texts myself I should write something about my methodology. Texts of revolutionary agitation (e.g. The Communist Manifesto or State and Revolution) and anthologies that covered various areas were encoded as “Social Science, General” because I couldn’t pin them down into one discipline. Marx’s Eighteenth Brumaire and Civil War in France could have been included in this category but I chose to instead include them in Sociology because they seemed more analytical than agitational. Also of note is the size of the Philosophy category. Many of the texts included under their heading also could have been labeled “Political Theory” or “Political Science” but were ambiguous enough for me to list them under Philosophy (e.g. Machiavelli’s The Prince or Locke’s Second Treatise of Government). This accounts for the large number of texts in the category. I included the Biography category for Engels’ On Marx, as his essays on Marx seemed more biographical than anything else, and it seemed odd to categorize his writings on his best friend as “Social Science.” Polanyi’s The Great Transformation was the only History entry (although it could perhaps have been included in the Economics category).
Analyzing the assignment count chart, we can see that whether or not we dissolve the “Social Science, General” category into the other categories, Economics is considerably outnumbered by the other disciplines combined. While Capital is a “Critique of Political Economy,” it seems to be more often taught alongside Sociology, Philosophy, and (perhaps) Political Science. This is not to say that its teaching is totally divorced from Economics (as it seems to be with History), but it is notable that Economics only has a minority share of assignments (Although it would hold a plurality if the philosophy category were broken up into smaller subsets). Furthermore the Economics texts that are taught alongside it are mostly drawn from 19th century “classical political economy,” with the exceptions being Keynes’ General Theory, Schumpeter’s Capitalism, Socialism, and Democracy and “heterodox” texts like The Great Transformation and The Theory of the Leisure Class. If we were to interpret this in a negative light we could see it pointing to Economics’ allergy to Marx, but in a more positive light we could argue that this points to Marx’s legacy as a thinker who was not employed in any one academic discipline but who freely cut across them when he found the need.
So what can we conclude about the state of teaching Capital? The answer is: not much! While this kind of data analysis is likely better than astrology or the old fashioned reading of tea leaves, the lack of completeness of the data set and the problems with data scraping are always going to cast the results into doubt. While “big data” analysis carries on the positivist dream of a true science of society, the conclusions it offers are often disturbingly subject to interpretation and speculation. We can say with some certainty that our results are mostly indicative of the state of American education, and exclusively Anglocentric, but these conclusions were defined at the start of the analysis and are not a result of it! On their FAQ page the authors write that: “Over time, the project needs individual faculty donations and access to institutional syllabus archives.” They plan to triple the number of entries in the database over the next year, but while this sounds impressive, once again it would place them at only about 3% of their target value. Big data analysis can be sound in principle, but while the field conjures of images of “immaterial” analytic wizardry, what is often required is labour, labour, and more labour to ensure that the data is actually “clean.” That much, at least, Marx would be unlikely to disagree with.
